Euskaltzaindiak saretutako EHHAko dokumentuak oinarri hartuta, lemekin letorkeen multzoketaren bila eginiko ahalegina
Laburpena:
Bilaketa bi daude honetan: EHHAko datuen trataera digitala, hasieran, eta datu horiek oinarri hartuta horien multzokatze analisia (Cluster Analisys), lematizazioarekin bat etorrita.
Nondik norakoa
Lan-jario bat aurkitu nahi dut, EHHAko datuetatik hasita lemen identifikaziora ahalik eta erarik automatizatuenean iristeko.
Helburu hori lortzeko ahaleginak EHHAko (Dialektologia batzordea 2018) datuekin egin ditut. Hain zuzen ere, 2062. mapako datuekin eraikitako HAIR.csv datuekin, ilea izendatzeko moduei buruzkoak1.
Pausuak, osorik zein zorrozteke daudenak, honela diseinatu ditut:
- Datuak kopiatu EHHAko PDFtik, itsatsi eta prestatu R-n kudeatzeko.
- R-ra sartu eta zutabe biko data framea egin (aldagai batean herriak, beste batean herrian jasotako hizkuntz formak).
- Formen arteko ALINE distantziak atera (Downey et al. 2008), alineR paketea erabilita (Downey, Sun, and Norquest 2017).
- Formen multzokatzeak Cluster Analysis teknikak erabilita.
Datu ezagun eta aztertuak direnez, multzo (cluster) kopuru aurrez jakina lortu nahi da, aurreikusitako lemekin bat letorkeena. - Egokitasunaren azterketa egiteko elementuak sortu:
- Dendograma
- Zerrendak
- Data Framea
Egokitasun azterketa horretan multzokatze teknika eta zatitze neurriak identifikatu behar dira, beste kasu batzuetan ere aplikagarriak ete diren aztertzeko
- Sortu data frame bat hiru aldagaiekin:
- Herria
- Batutako hizkuntz forma
- Multzo kodea
Multzo kode bakoitza lema bati egokitzea espero da, erraz ordezkatzeko modukoa.
- Beste datu multzo batzuekin saiatu teknikotan.
Datuen prestaketa
R-ra ekarri aurretik, datuen prestaketa eta garbiketa egin behar da, nik hurrengo pausen bitartez egitea pentsatu dut:
- PDFan aukeratu
- Kate testu editorean itsatsi (erdiko erroberarekin klik)
- Bertan lehenengo garbiketa bat
Esate baterako:- (mark.) dioten testuak eta (?) oharrak ezabatu.2
- Herrialdeen izenak ezabatu.
- Lerro bakarrean utzi herri bakoitza.
- Aukeratu eta LibreOffice Calc-en itsatsi, banatzailetzat puntu biak (:) eta komak (,) hartuta.
- Gorde fitxategi hori .csv formatuan. Herriak beste lerro izango ditu eta erantzun gehien hartutako herriko erantzun kopurua beste zutabe.
# Datuak 'hair' izenko data frame batera sartu
hair <- read.table("./HAIR.csv",
header = F,
sep = ",",
stringsAsFactors = F)
knitr::kable(hair[120:132,], caption = "Data framearen zenbait lerro eta aldagai guztiak")| V1 | V2 | V3 | V4 | V5 | |
|---|---|---|---|---|---|
| 120 | Arrueta | bílo | |||
| 121 | Baigorri | ile | |||
| 122 | Bastida | íle | bíle (?) | ||
| 123 | Behorlegi | biló | |||
| 124 | Bidarrai | βiló | íle | ||
| 125 | Ezterenzubi | bílo | |||
| 126 | Gamarte | biló | |||
| 127 | Garrüze | bílo | |||
| 128 | Irisarri | bílo | |||
| 129 | Izturitze | bílho | ilhe (?) | ||
| 130 | Jutsi | bilho | |||
| 131 | Landibarre | biluá | bírua | bílo | ílea |
| 132 | Larzabale | bilho |
Data frameak aldagai asko ditu (5) eta lerroak/herriak 145 dira.
Ordena zuzendu behar da honelako egiturara:
- Lehenengo aldagaia herriaren izena (errepikatu egingo da)
- Bigarren aldagaia hizkuntz forma (ez da errepikatuko herrian bertan)
Nahi den egokitzapen horretarako, sortuko ditugu data frameak erantzun-aldagaiak beste, gero denak data frame bakarrean batzeko.
# Banatu
df.zerrenda <- c()
for(i in 1:length(names(hair))) {
if(i==1){
next
}
ixena <- paste("df",i, sep = "")
assign(ixena, data.frame(HERRIA = hair[,1], ERANTZUNAK = hair[,i]))
# print(ixena)
df.zerrenda <- c(df.zerrenda, ixena)
}
# Batu
df.hair <- dplyr::bind_rows(df2, df3, df4, df5)
# Kendu balio sobrakoak
df.hair <- df.hair[!df.hair[,2]=="",]
# Taula bat, aztertzeko
knitr::kable(tail(df.hair, 15), caption = "data framearen azken balioak")| HERRIA | ERANTZUNAK | |
|---|---|---|
| 255 | Makea | *íle |
| 258 | Senpere | *ile͜óndo |
| 260 | Uztaritze | *βiló |
| 261 | Aldude | *biló |
| 263 | Armendaritze | biló |
| 264 | Arnegi | ilé |
| 267 | Bastida | bíle (?) |
| 269 | Bidarrai | íle |
| 274 | Izturitze | ilhe (?) |
| 276 | Landibarre | bírua |
| 282 | Domintxaine | bilhó |
| 283 | Eskiula | bilhúk |
| 386 | Suarbe | íʎa |
| 421 | Landibarre | bílo |
| 566 | Landibarre | ílea |
Oraingo data frameak 2 aldagai eta 173 lerro ditu
Azentu eta karaktere konfigurazio batzuk aldatu behar dira, abisurik ez emateko.
Oharra: Puntu honetan berrikus daitezke euskarazko konfigurazio batzuk sinplifikatzea, alineR-ek lana hobeto egiteko, esate baterako, bilho/bilo erakoak batu, lh guztiak l hutsera pasatuaz. Berdin egin behar litzateke, hala egitera, kh eta antzerako kasuekin.
ipa.garbifuntzioa eraiki behar da
# Irteerako datuak garbitzeko, arazodun azentuak-eta ezabatu
# Funtzio egin behar da
# Aldagaiak batu bakarrean.
# ipa.garbi(df.hair)
df.hair[,2] <- gsub("r̄",
"r",
df.hair[, 2])
df.hair[, 2] <- gsub("i̯",
"i",
df.hair[, 2])
df.hair[, 2] <- gsub("ɛ́",
"ɛ",
df.hair[, 2])
df.hair[, 2] <- gsub("͜ó",
"o",
df.hair[, 2])
df.hair[, 2] <- gsub("\\*", "", df.hair[, 2])
df.hair[, 2] <- gsub("\\)", "", df.hair[, 2])
df.hair[, 2] <- gsub("\\(", "", df.hair[, 2])
df.hair[, 2] <- gsub("\\?", "", df.hair[, 2])ALINE distantzien gainetiko azterketa bat
Darabiltzagun datuekin aldaera batzuen arteko ALINE distantzi linguistikoa aztertuko dugu. Oinarritzat Azkoitiako íʎe aldaera erabili da beste modu batzuekin alderatzeko.
- \(d_{ALINE( íʎe - íʎe)}\) Azkoitia-Bergara
- \(d_{ALINE( íʎe - iʎé)}\) Azkoitia-Azpeitia
- \(d_{ALINE( íʎe - úle)}\) Azkoitia-Arrasate
- \(d_{ALINE( íʎe - úʎe)}\) Azkoitia-Orozko
- \(d_{ALINE( íʎe - ílɛ)}\)Azkoitia-Lekaroz
- \(d_{ALINE( íʎe - íle)}\)Azkoitia-Urdiain
- \(d_{ALINE( íʎe - βurúkoiʎé)}\) Azkoitia-Ataun
- \(d_{ALINE( íʎe - bílho)}\) Azkoitia-SantaEngrazi
library(alineR)
# - d~(Azkoitia-Bergara)~
# Balio berberak
df.hair[46,2]; df.hair[50, 2]; aline(df.hair[46,2], df.hair[50, 2])## [1] " íʎe"## [1] " íʎe"## [1] 0# - d~(Azkoitia-Azpeitia)~
# Azentu desberdina
df.hair[46,2]; df.hair[47, 2]; aline(df.hair[46,2], df.hair[47, 2])## [1] " íʎe"## [1] " iʎé"## [1] 0# - d~(Azkoitia-Arrasate)~
# Grafema desberdin bi
df.hair[46,2]; df.hair[42, 2]; aline(df.hair[46,2], df.hair[42, 2])## [1] " íʎe"## [1] " úle"## [1] 0.2461538# - d~(Azkoitia-Orozko)~
# Bokal bat aldatzen da
df.hair[46,2]; df.hair[29, 2]; aline(df.hair[46,2], df.hair[29, 2])## [1] " íʎe"## [1] " úʎe"## [1] 0.1538462# - d~(Azkoitia-Urdiain)~
# Kontsonante bat aldatzen da
df.hair[46,2]; df.hair[98, 2]; aline(df.hair[46,2], df.hair[98, 2])## [1] " íʎe"## [1] " íle"## [1] 0.09230769# - d~(Azkoitia-Lekaroz)~
# Hurreko bokal bat aldatzen da
df.hair[46,2]; df.hair[92, 2]; aline(df.hair[46,2], df.hair[92, 2])## [1] " íʎe"## [1] " ílɛ"## [1] 0.09230769# Azkoitia-Ataun
df.hair[46,2]; df.hair[45,2]## [1] " íʎe"## [1] " βurúkoiʎé"aline(df.hair[46,2], df.hair[45,2],
mark = TRUE,
m1 = "β",
m2 = "b")## [1] 0.5357143# Azkoitia-Santa engrazi
knitr::kable(
aline(df.hair[46,2], df.hair[143,2], mark = T, alignment = T),
caption = paste(df.hair[46,2], df.hair[143,2])
)| pair1 | |
|---|---|
| w1 | íʎe |
| w2 | bílho |
| scores | 0.51 |
| a1 | | - í - ʎ | |
| a2 | | b í l h | |
Distantzien matrizea konputatu
Horretarako Marcelino de la Cruzek pasatutako irtenbidea erabili dut: aline.dist funtzioa begizta batez eraikita.
# Marcelino de la Cruz Rotek r-es-HELP zerrendan emandako irtenbidetik
# Funtzio bat ALINE distantzia-matrizea konputatzeko
aline.dist <- function(x0, namesx0) {
require(alineR)
ok <- !is.na(x0)
x0.ok <- x0[ok]
namesx0.ok <- namesx0[ok]
x <- rep(x0.ok, length(x0.ok))
y <- rep(x0.ok, each = length(x0.ok))
gauza <- aline(w1 = x, w2 = y, m1 = "β", m2 = "b")
gauza.m <- matrix(gauza, nr = length(x0.ok), nc = length(x0.ok))
dimnames(gauza.m) <- list(namesx0.ok, namesx0.ok)
return(as.dist(gauza.m))
}# Distantzien konputazioa bera
d.aline.hair <- aline.dist(df.hair[,2], df.hair[,1])
# Datuen baztertxu bat erakutsi
knitr::kable(as.matrix(d.aline.hair)[2:25,2:9],
digits = 3,
caption = "Distantzien matrizearen ertz bat")| Arrieta | Bakio | Bermeo | Berriz | Bolibar | Busturia | Dima | Elantxobe | |
|---|---|---|---|---|---|---|---|---|
| Arrieta | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Bakio | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Bermeo | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Berriz | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Bolibar | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Busturia | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Dima | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Elantxobe | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Elorrio | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Errigoiti | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Etxebarri | 0.169 | 0.169 | 0.169 | 0.169 | 0.169 | 0.169 | 0.169 | 0.169 |
| Etxebarria | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Gamiz-Fika | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Getxo | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Gizaburuaga | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Ibarruri (Muxika) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Kortezubi | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Larrabetzu | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Laukiz | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Leioa | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Lekeitio | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Lemoa | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Lemoiz | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Mañaria | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
Multzoak sortzeko modu batzuk
Azterketa hau R-k bere base paketean eskaintzen dituen zortzi multzokatze moduak erabilita dago eginda. Hurrengo tartean zortzi era horiek batera erakusten dira. Hori egitea proposatzen da zein multzokatze era komeni litzatekeen era grafikoan aztertzeko.
Aztergai darabiltzagun datuetan zazpi lema identifikatu behar dituela ematen du:
- ILE
- ULE
- BILO
- KALPAR
- TXIMA
- BURUKOILE (Ataunen soilik)
- ILEONDO (Senperen soilik)
Dendogrametan 7 multzokatze aukeratzeko eskatzen da, ea bilatzen den multzokatze hori zein erak ematen duen, batek ematen badu, behintzat.
# MULTZOKATZEAK
erak <-c("ward.D", "ward.D2", "single", "complete",
"average", "mcquitty", "median","centroid")
# IRUDI BAT MULTZOKO
for(i in erak) {
clus.x <- hclust(d.aline.hair, method = i)
plot(clus.x,
cex = 0.5,
labels = paste(df.hair[,1],df.hair[,2], sep = "-"),
main = "Lemen bila"
)
rect.hclust(clus.x,
k=7,
border="red")
}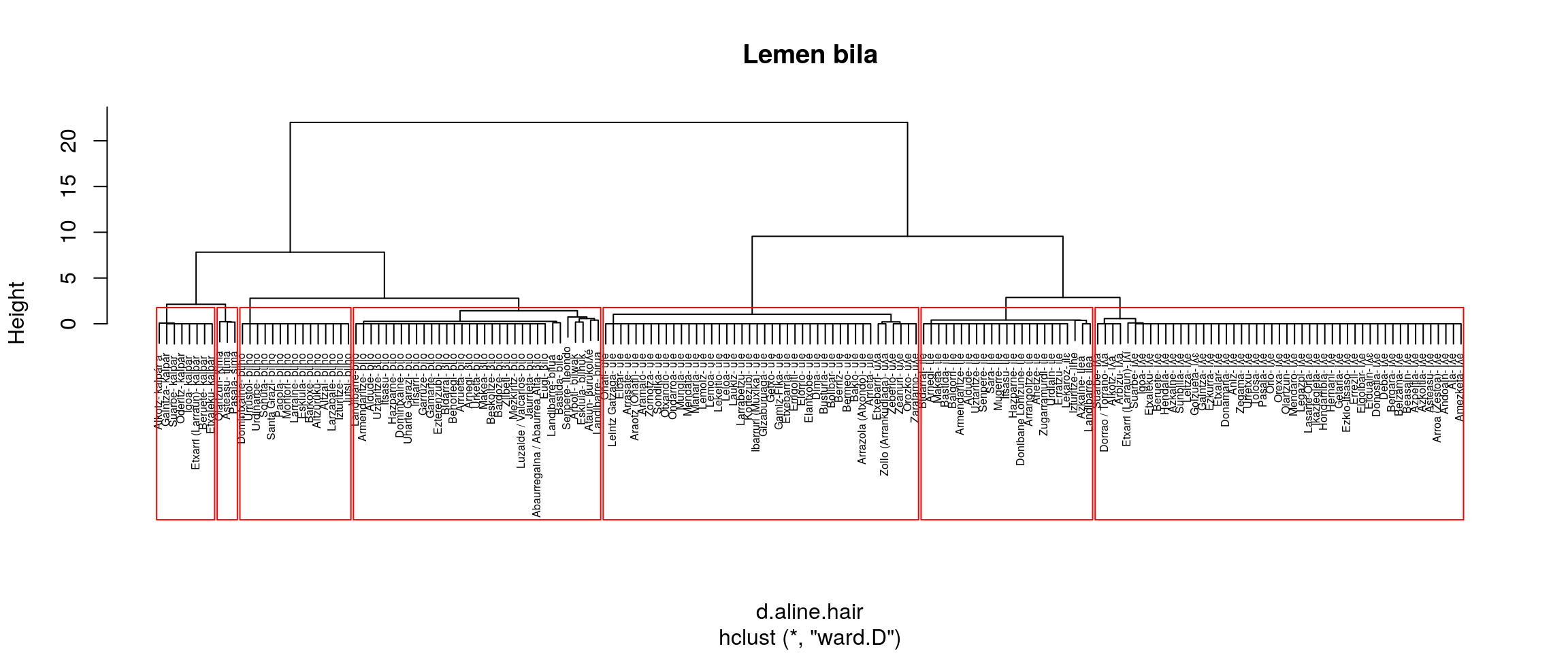
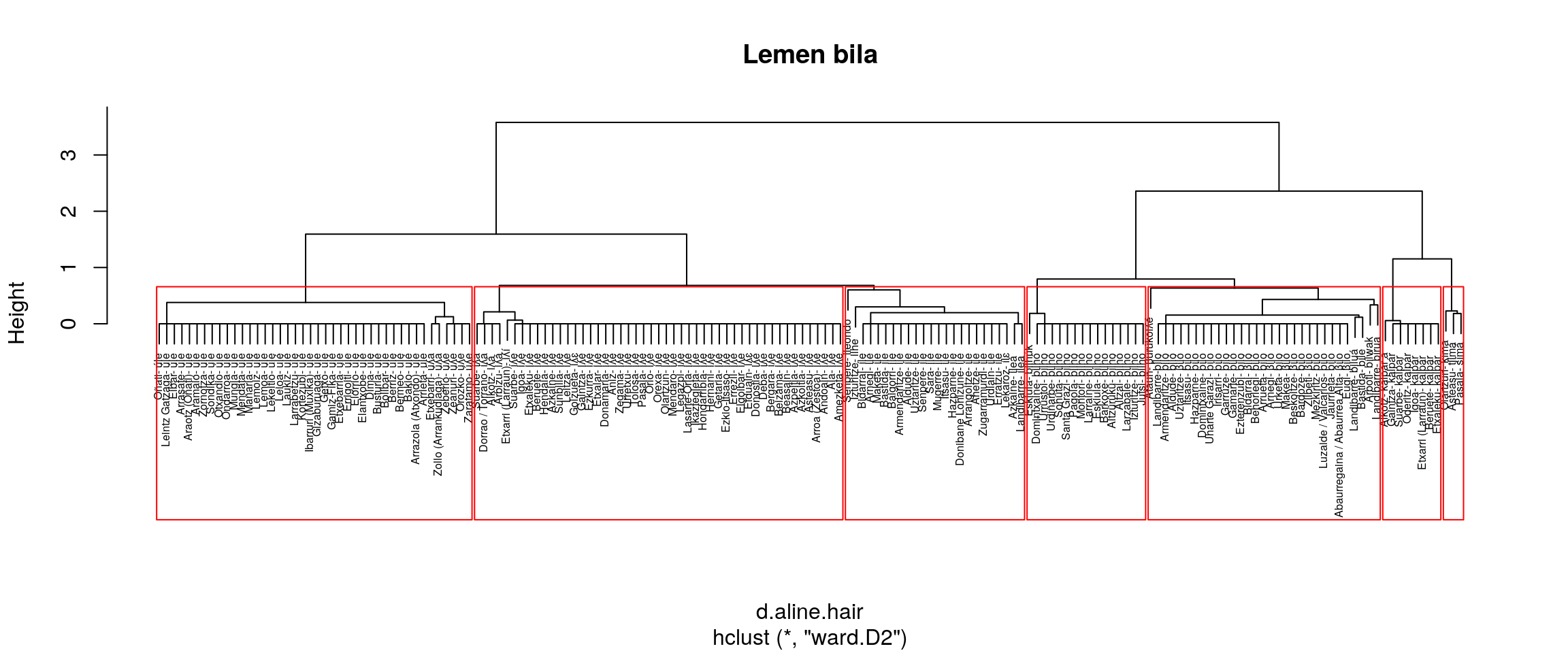
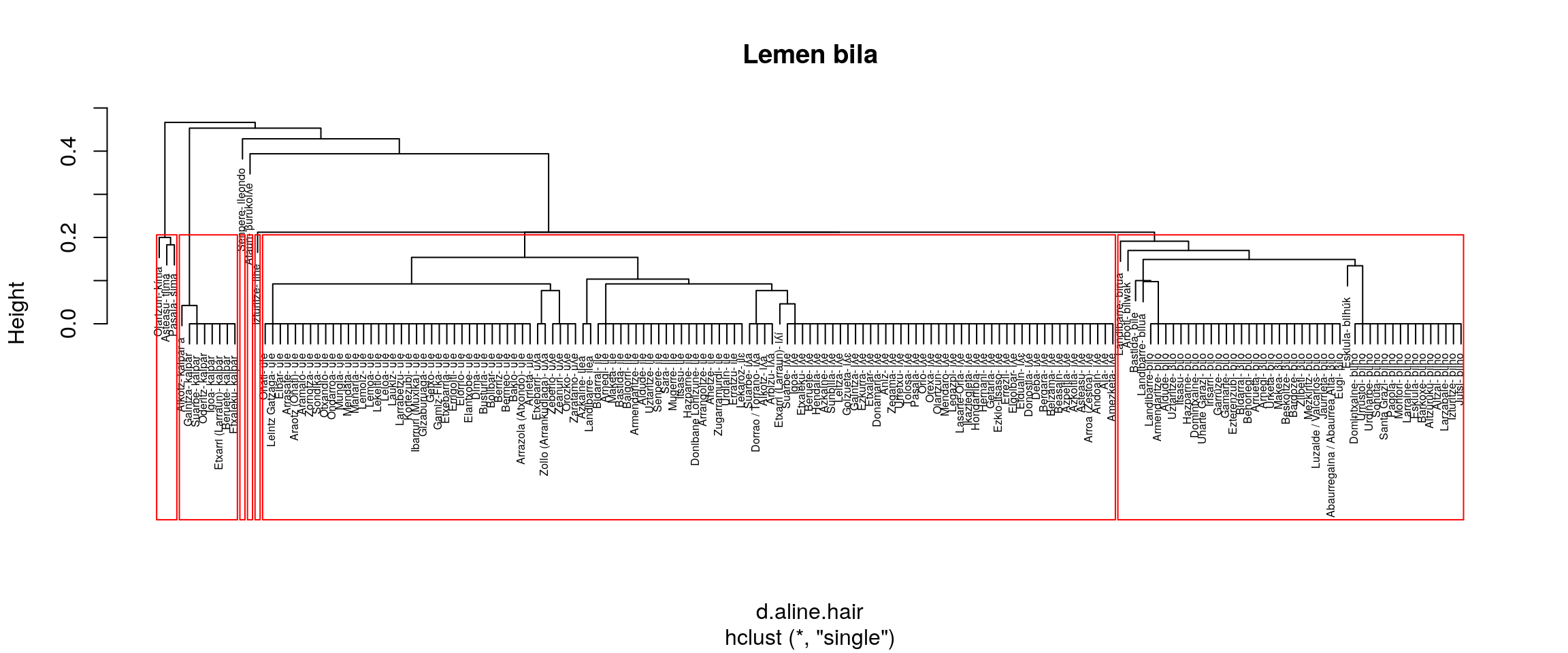
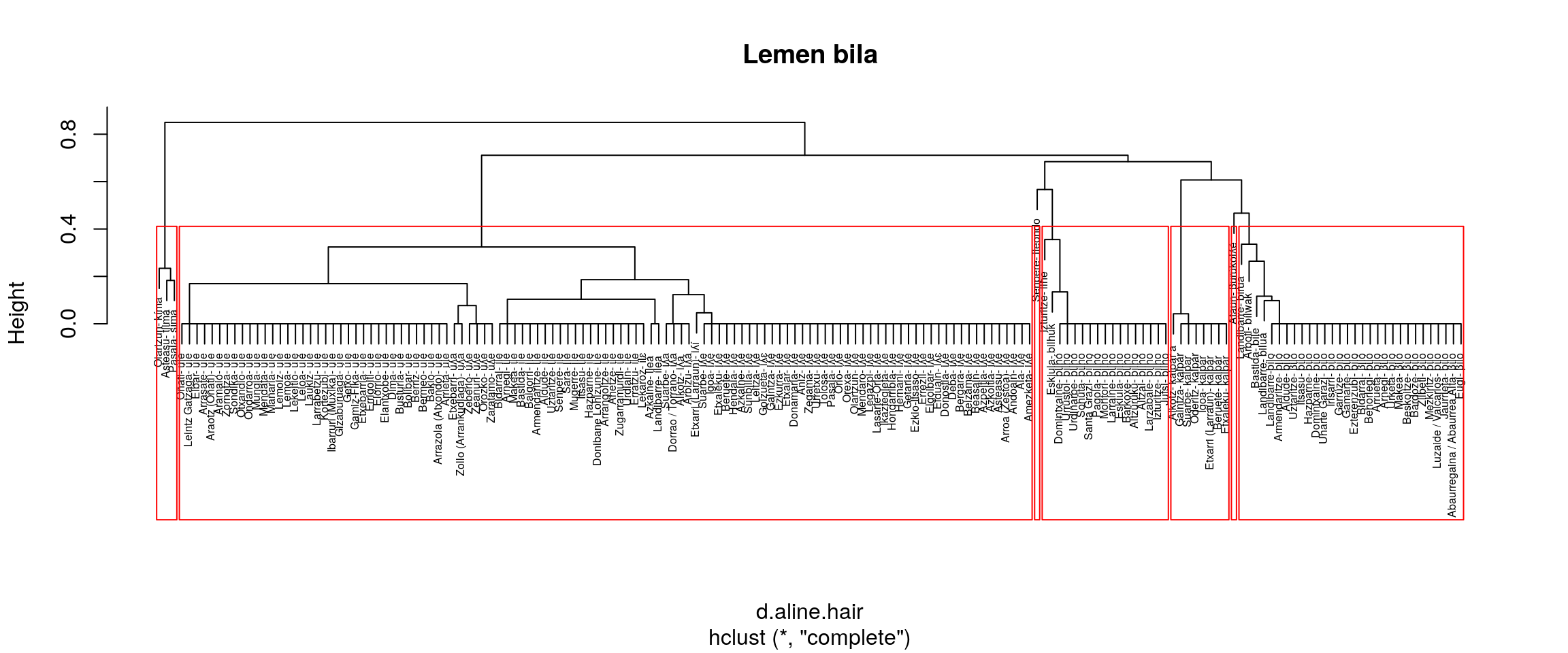
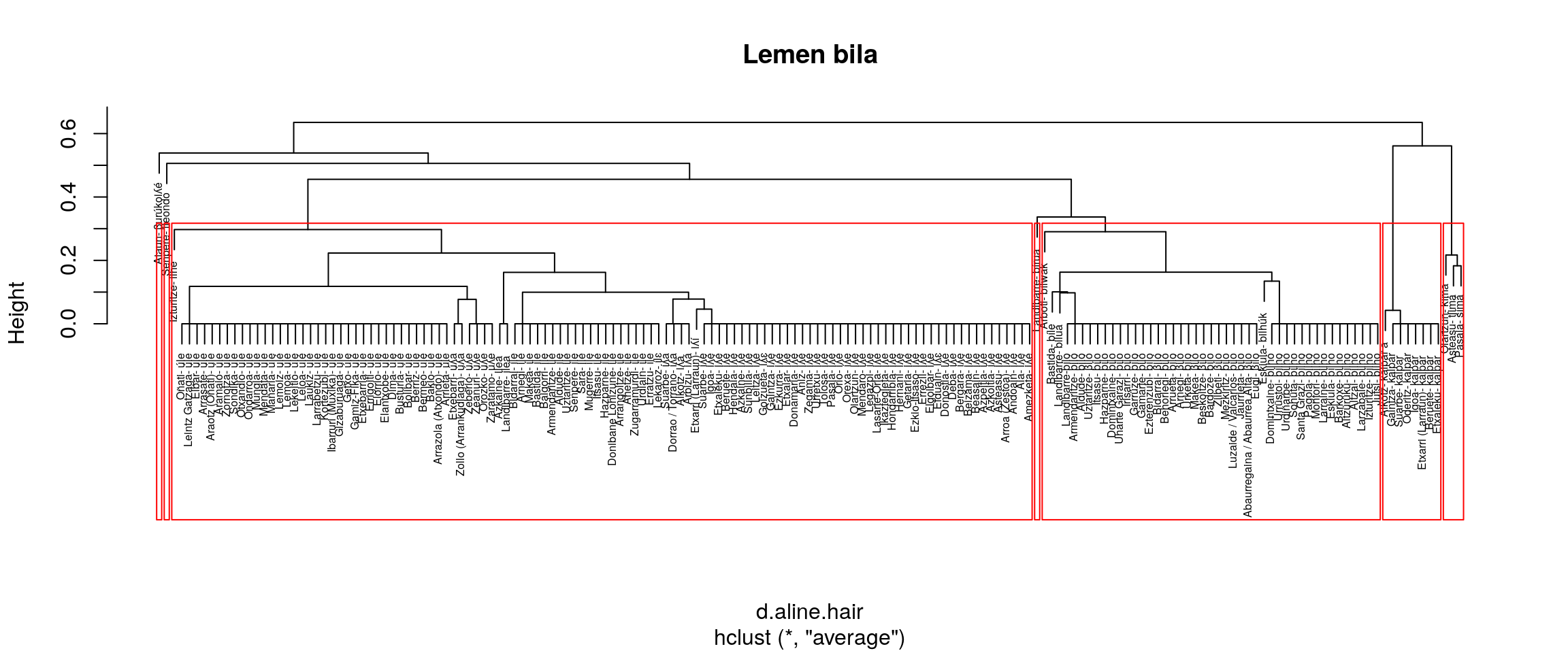
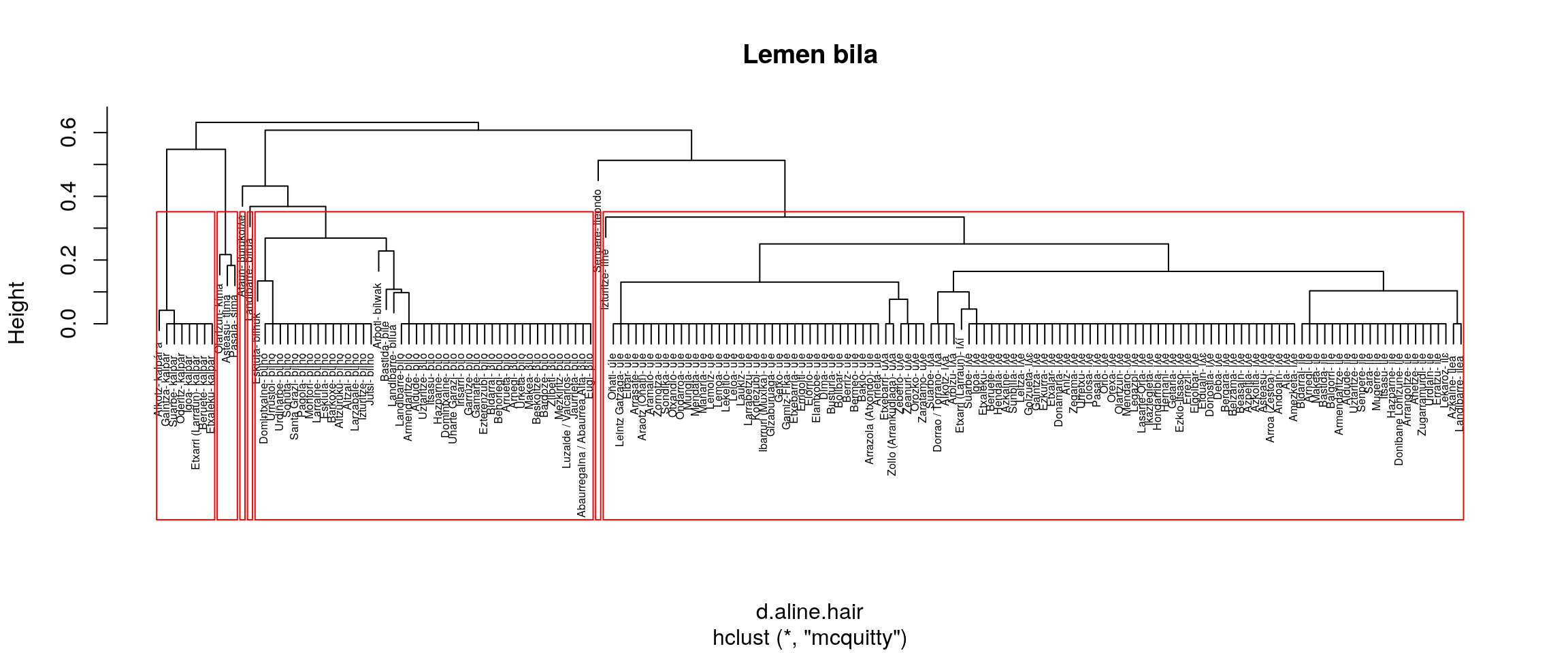

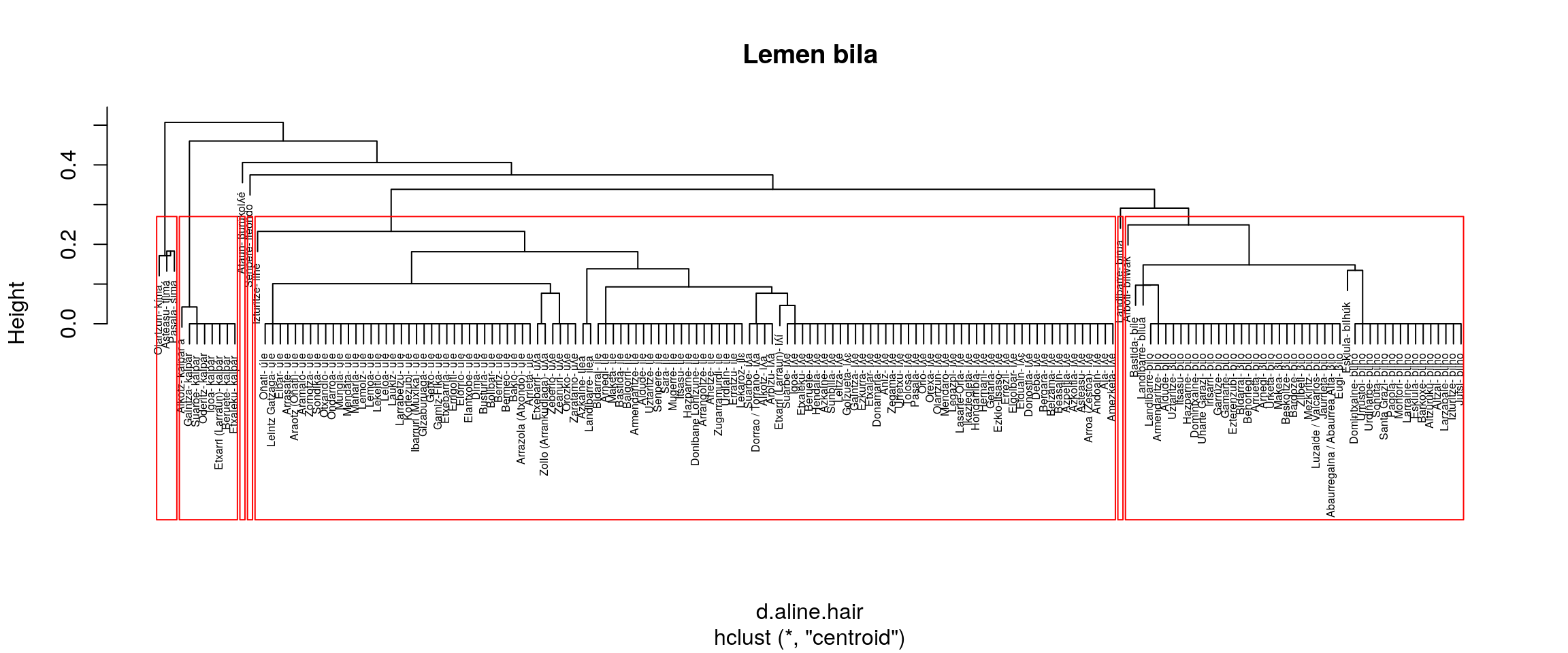
Irudien gainetiko azterketa bat:
- ward.D multzokatze era
- Banatzen ditu ile eta iʎe
- Batzen ditu bilwak, burukoilea eta biroa
- ward.D2
- Aurrekoaren antzera.
- ILEONDO eta ILE batera ematen ditu
- single
- Batzen ditu ULE eta ILE
- Aurrekotik bereiz ematen du ILHE
- Kima eta Txima banaturik ematen ditu
- complete
Aurrekoaren moduan, ILHE eta ILE banatzen ditu. Baina batzen ditu ULE eta ILE. - average
- Aurrekoaren antzera
- mcquitty
- Batera ILE eta ULE
- Bereiz ILHE
- median
- Berdintsu
- centroid
- Berdintsu
Lema bat etiketa-zenbaki bik adierazi behar dutela jakin arren, ez du ematen oraingo pausuan berebizikoa izango denik.
Oharra: Erabaki behar da ea erabilgarria den ala ez.
Bigarren ahalegina
Zortziko taldekatzeak ezin erantzun diezaioke gure planteamenduari, datu hauek erabilita. Bide posibleak bi dira, beraz:
- Datuak egokitu. Multzokatze prozesuan idazkera/kodetze moduak hurrundutako batzuk hurreratu.
EB: lh -> l, edo antzerakoak, aurretik adierazi den moduan - Multzokatze prozesua multzo gehiagotan aztertu.
# MULTZOKATZEAK
erak <-c("ward.D", "ward.D2", "single", "complete",
"average", "mcquitty", "median","centroid")
# IRUDI BAT MULTZOKO
for(i in erak) {
clus.x <- hclust(d.aline.hair, method = i)
plot(clus.x,
cex = 0.5,
labels = paste(df.hair[,1],df.hair[,2], sep = "-"),
main = "Lemen bila"
)
rect.hclust(clus.x,
k=8,
border="blue")
}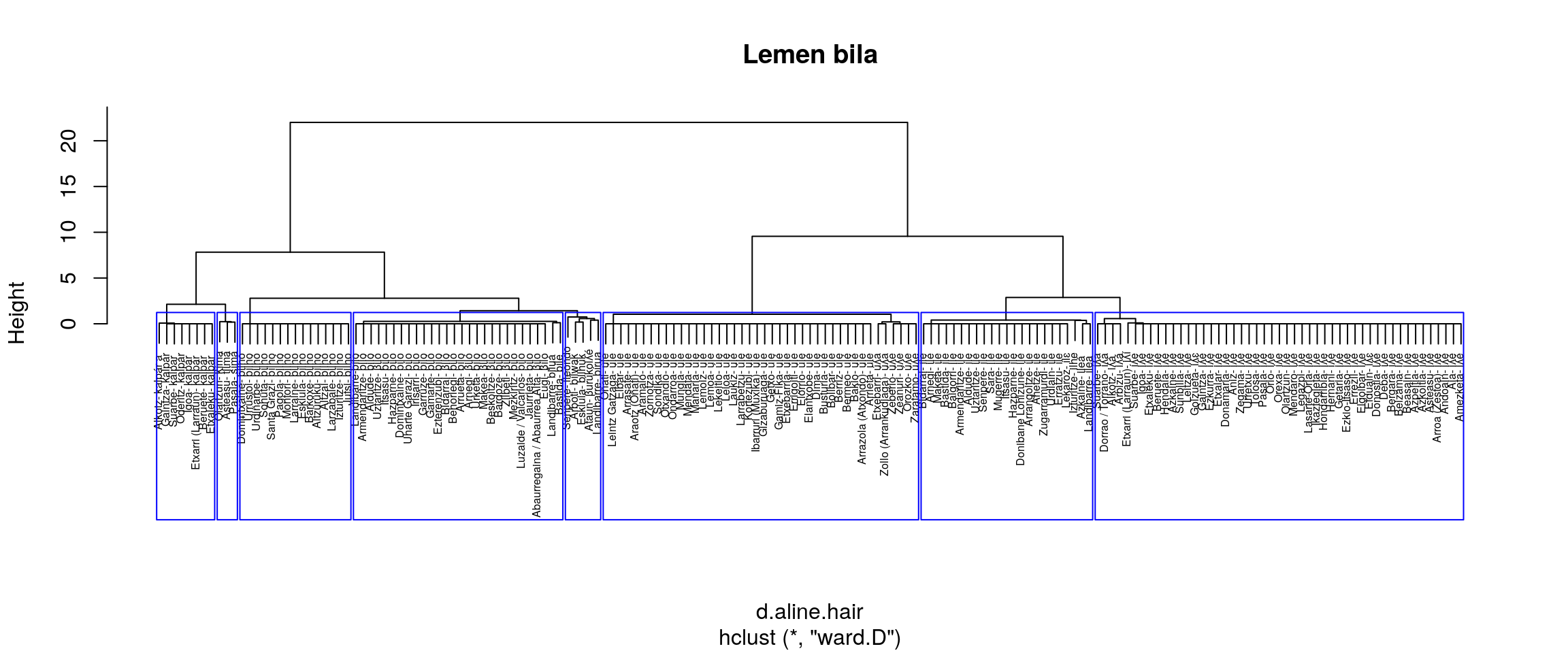
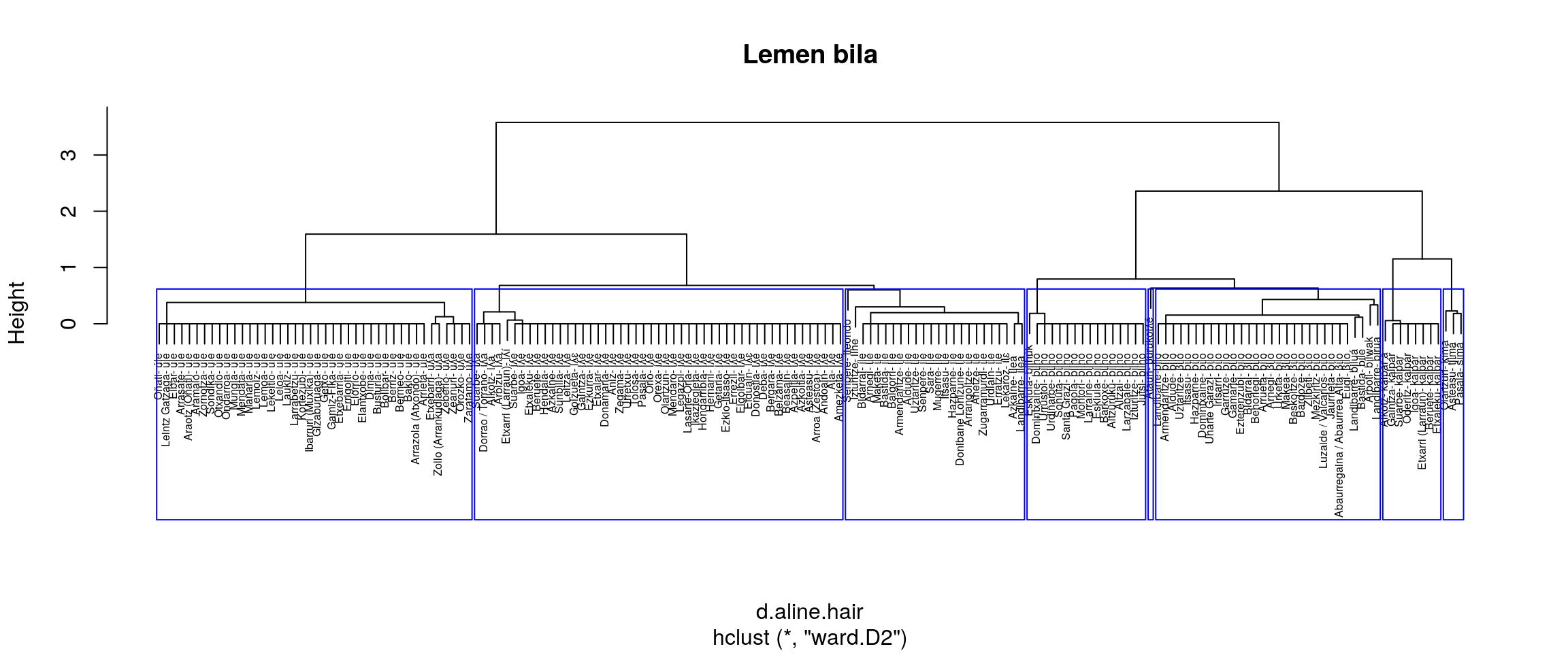
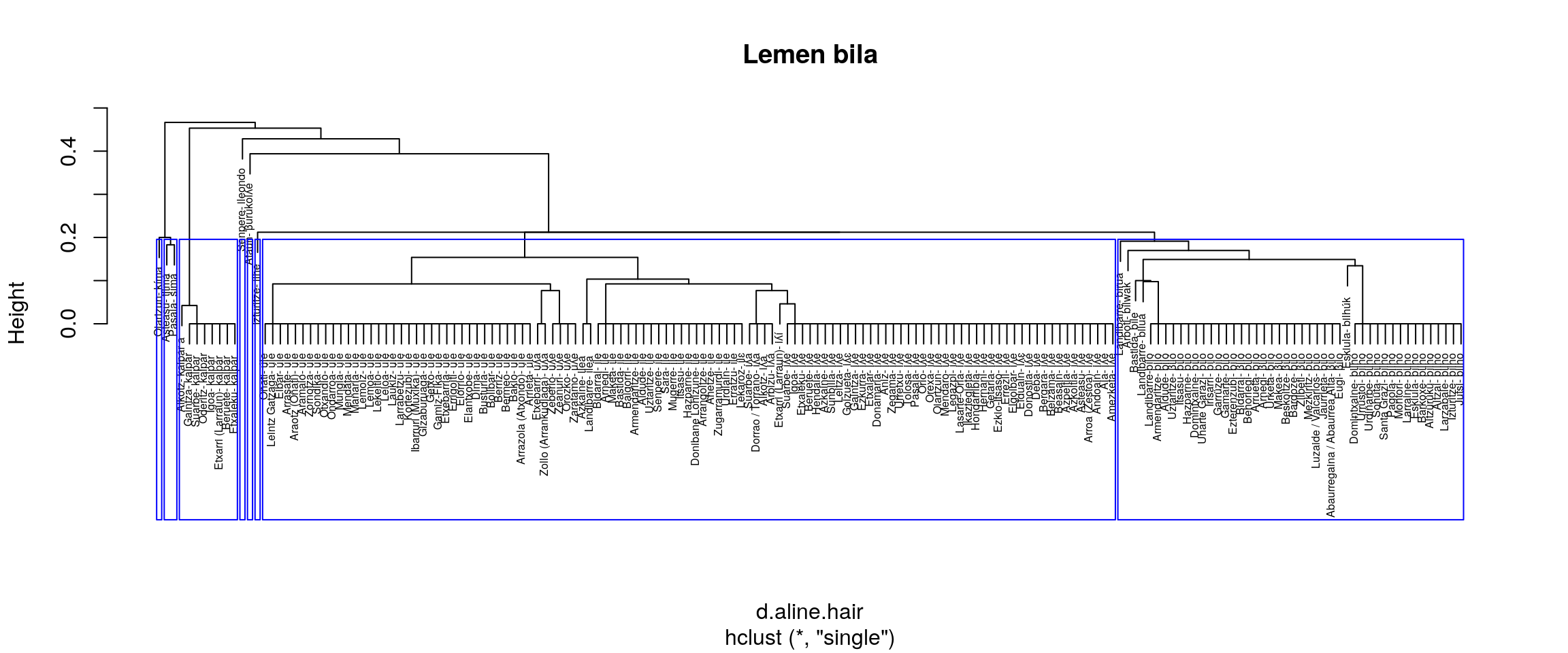
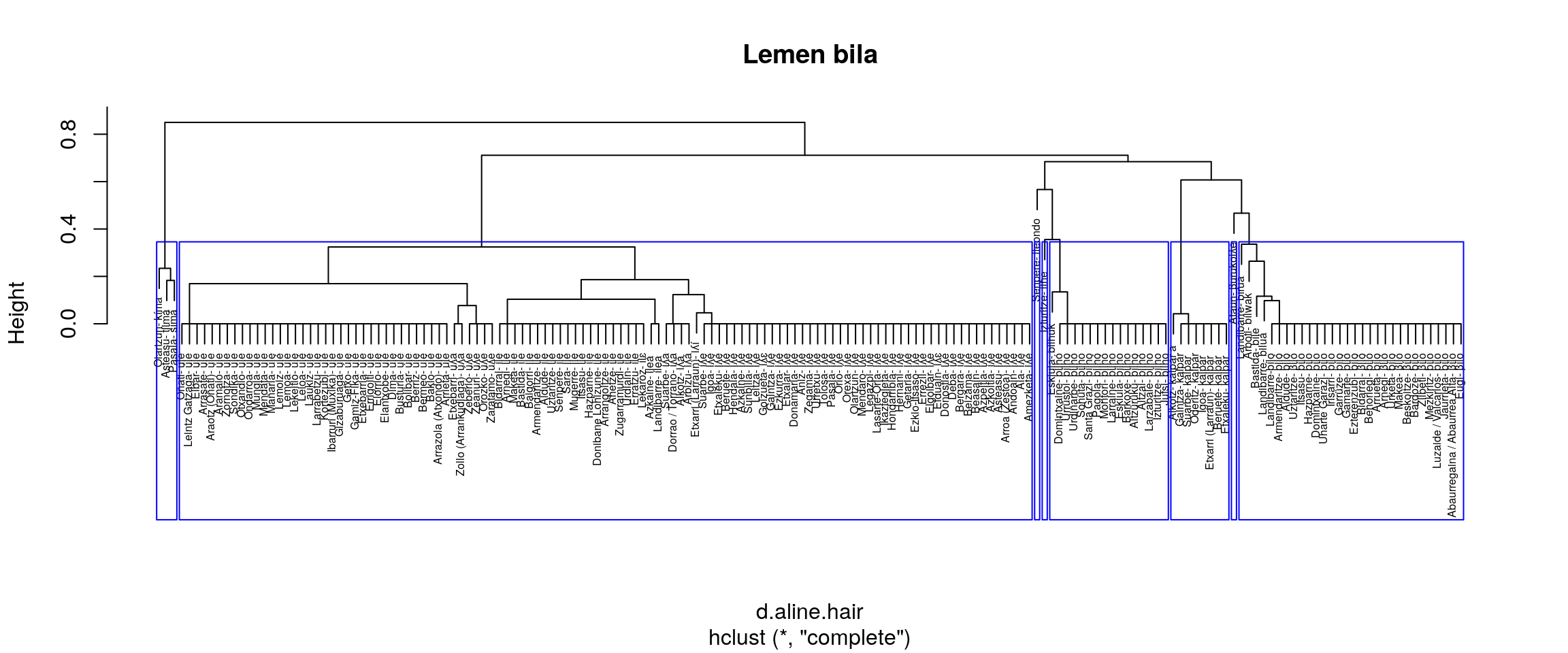
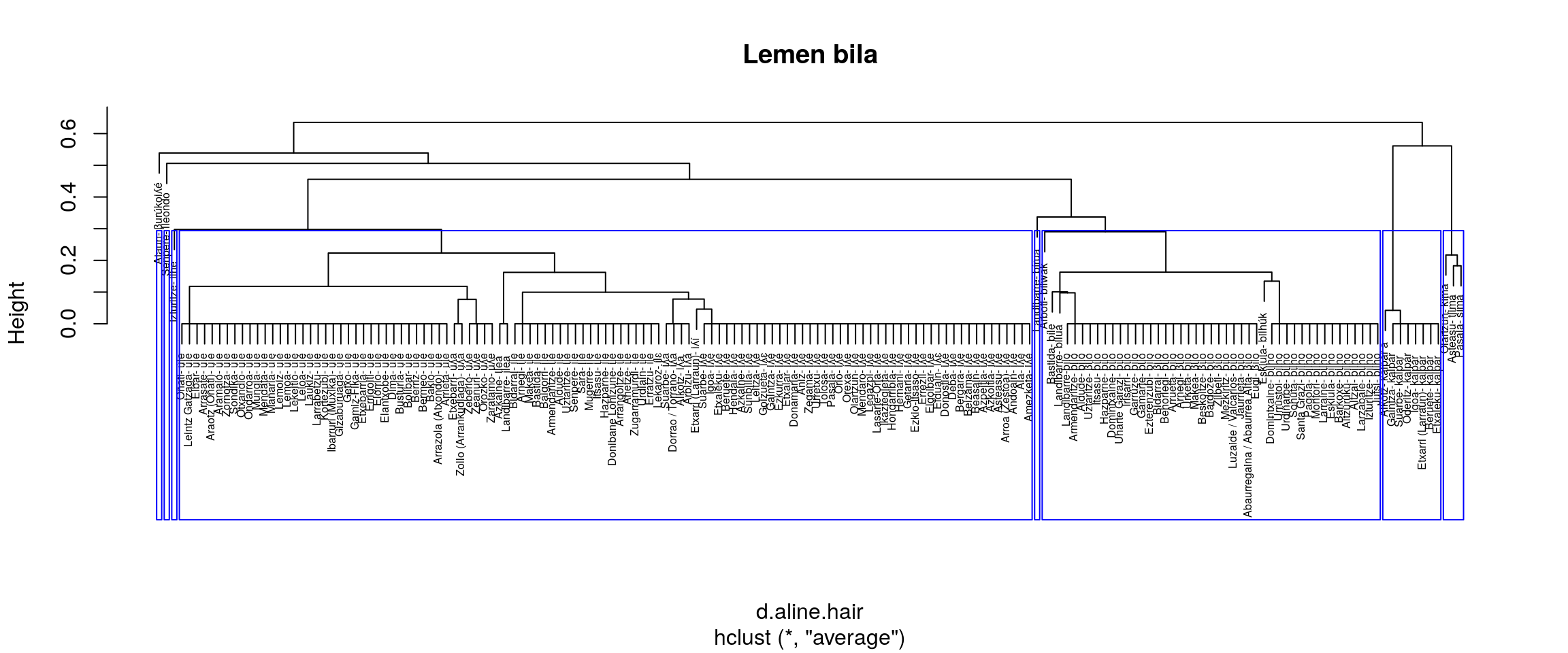
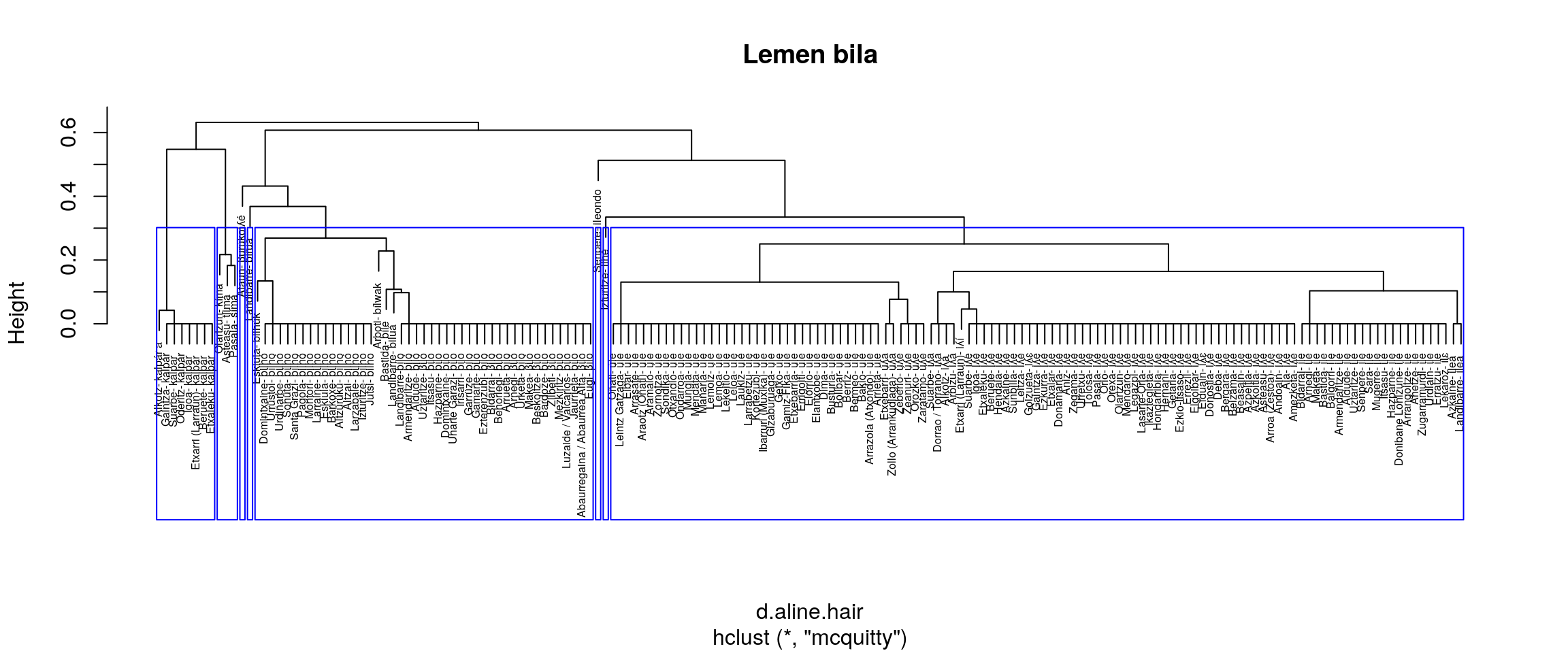
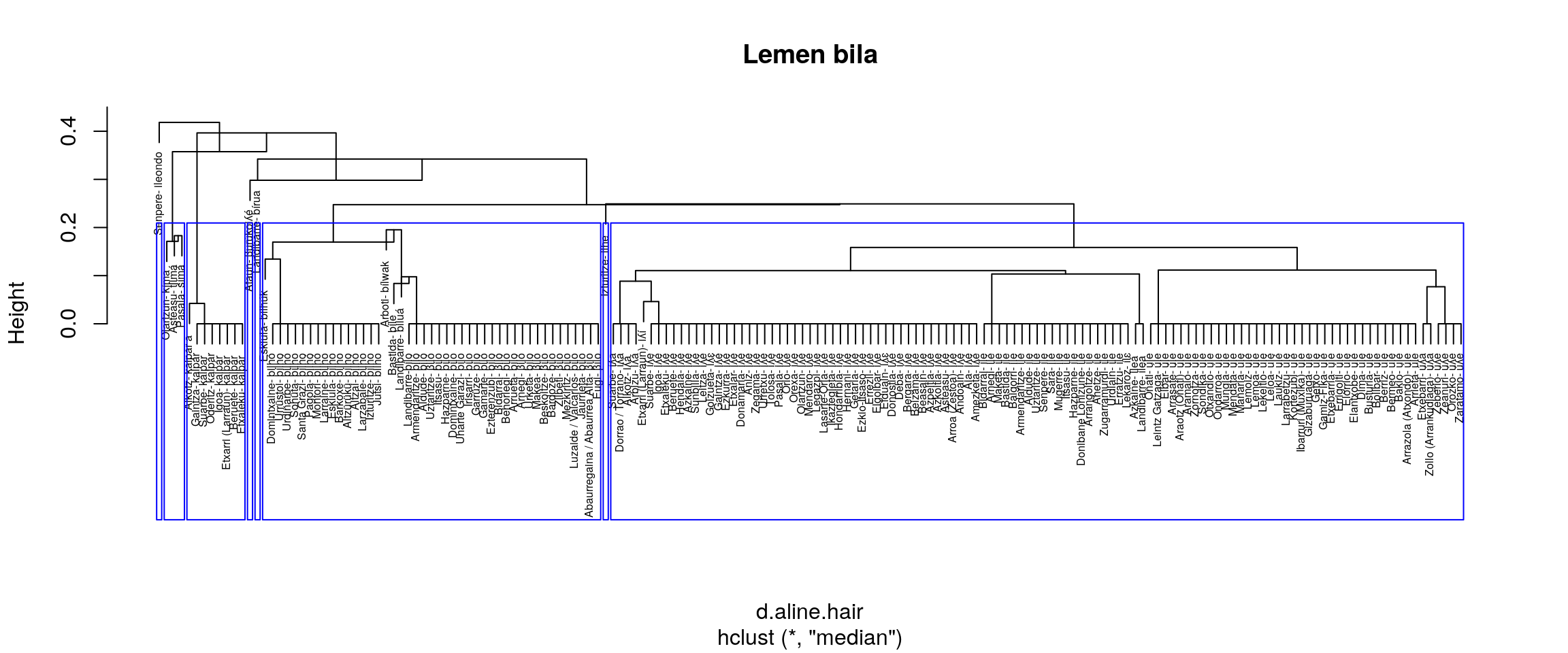
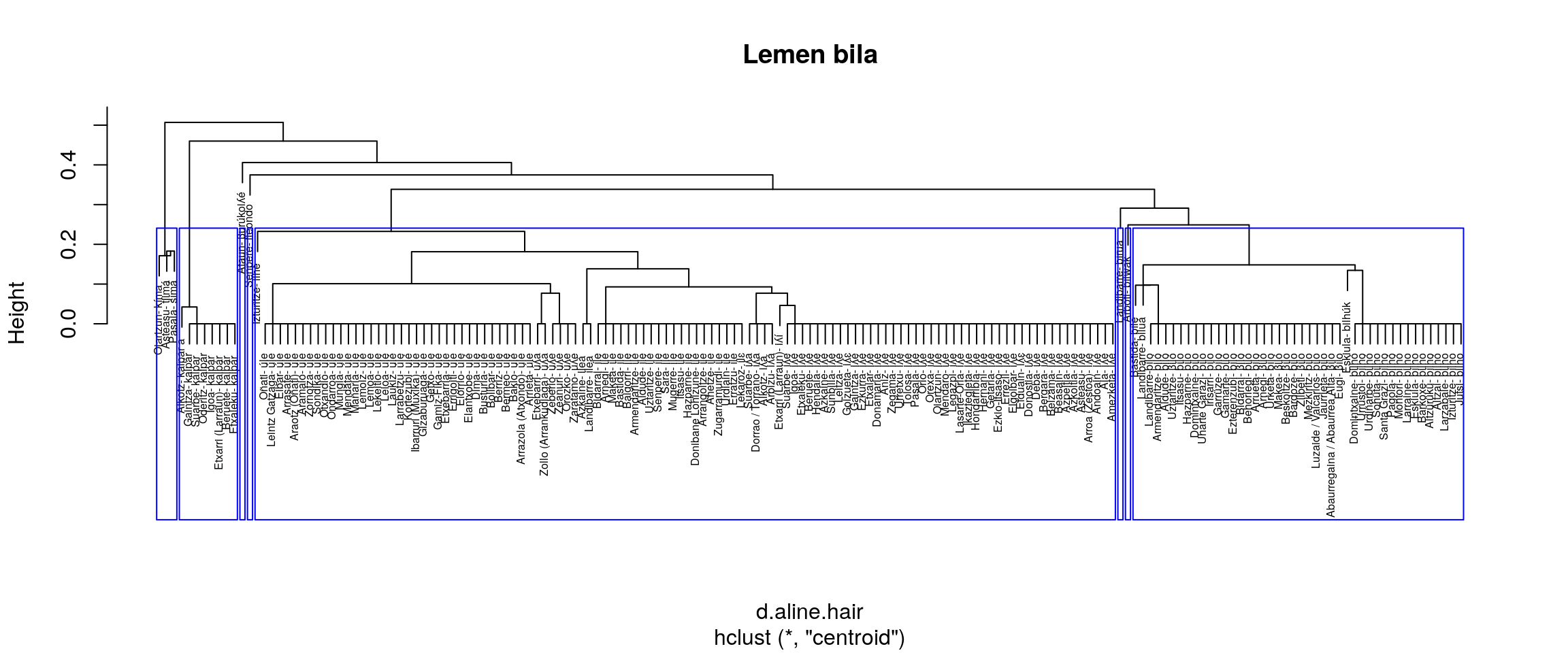
Aurreko irudiak aztertuta (eskuineko botoiarekin pantaila osoan ikus daitezke), ematen du gure helburuetatik hurbilen dagoen multzokatze era ward.D2 dela. Baina, datuak dauden moduan Senpereko ileondo forma ILE lemaren barruan kokatzen du eta banaketa bat markatzen du BILO eta BILHO artean.
Datuak zuzendu ezik, etiketa bik batu behar lukete ordezkatze prozesuan.
Hirugarren ahalegina
Honetan soilik aztertuko da ward.D2 multzokatze era, baina aurretik datuen lh formak l-ra igaro eta distantzi matrizea berreraikita.
# df barria
df.hair1 <- df.hair
df.hair1[, 2] <- gsub("lh", "l", df.hair1[, 2])
# distantzi matrize berria
d.aline.hair1 <- aline.dist(df.hair1[,2], df.hair1[,1])
clus.hair1 <- hclust(d.aline.hair1, method = "ward.D2")
plot(
clus.hair1,
cex = 0.5,
labels = paste(df.hair[, 1], df.hair[, 2], sep = "-"),
main = "Lemen bila v3"
)
rect.hclust(clus.hair1,
k = 7,
border = "green")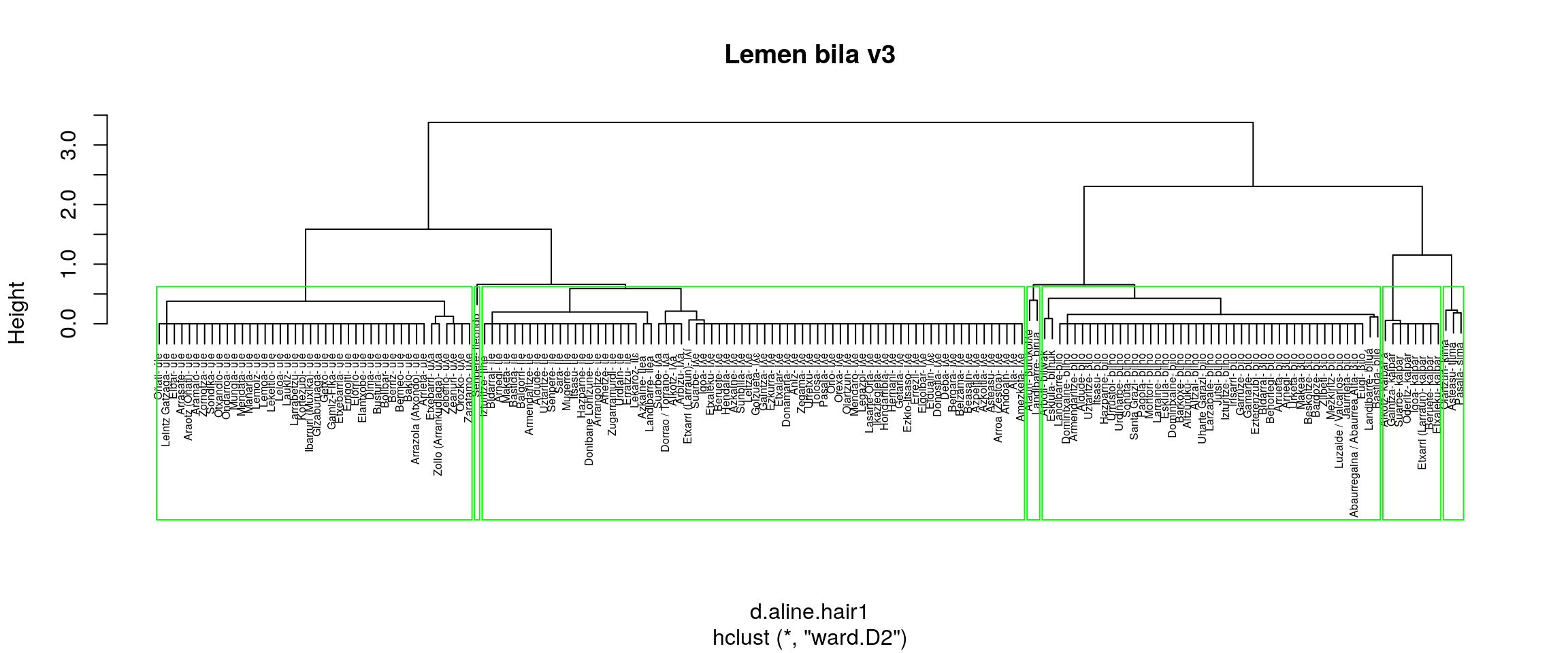
Azken multzoek ere ez diote ondo erantzuten, Landibarreko biruak forma eta Ataungo burukoile elkarrekin ematen baititu. Hala ere, ematen du bidea hortik pasa daitekeela.
Zenbat multzo (cluster) egin ?
GARATZEKO
Ideia hutsa da. k-mean teknikak erabilita, badago era bat grafikoki aztertzeko ea zenbat k egitea komeni den. Multzokatzeen Analisirako gidan (Kassambara 2017) zehazten da zelan egin3.
Aztertu ia alderik dagoan multzokatzeko aldaeren artean.
Funtzioa egin behar da.
Multzoak zatitu
Multzo era egokia aukeratutakoan, multzoak zehaztu eta mugatu behar dira. Hemen agertzen den multzokatze erak ez du beste helbururik bat aukeratuta programazioa garatzea baino.
Oinarrizko galdera: Esperotako multzoak bat datoz ekuz egindako lematizazio lanarekin?
Zerrendak (herrienak)
Erantzun honetan oinarritua.
# Prozesu osoa HAMAR multzotan banatu
kutri <- cutree(clus.hair1, k = 7)Cluster arazoduna:
names(kutri)[kutri==3]## [1] "Ataun" "Landibarre"Datu antolatuekin data.frame bat sortu
Datuok berrantolatu daitezke eta .csv artxibo batera zuzenean atera.
df.kutri <- data.frame(HERRIAK = names(kutri),
FORMAK = df.hair[,2],
MULTZOA = kutri)
# df.kutriDatuen aurkezpen ordenatua
Lehenengo zutabean herriak zerrendatzen dira, bigarrenean hizkuntz formak, eta azkenik, hirugarrenak diosku zein multzotakoa den elementua.
knitr::kable(dplyr::arrange(df.kutri, kutri), row.names = F)| HERRIAK | FORMAK | MULTZOA |
|---|---|---|
| Arrazola (Atxondo) | úle | 1 |
| Arrieta | úle | 1 |
| Bakio | ulé | 1 |
| Bermeo | ulé | 1 |
| Berriz | úle | 1 |
| Bolibar | úle | 1 |
| Busturia | ulé | 1 |
| Dima | úle | 1 |
| Elantxobe | ulé | 1 |
| Elorrio | úle | 1 |
| Errigoiti | úle | 1 |
| Etxebarri | úʎa | 1 |
| Etxebarria | úle | 1 |
| Gamiz-Fika | ulé | 1 |
| Getxo | úle | 1 |
| Gizaburuaga | úle | 1 |
| Ibarruri (Muxika) | úle | 1 |
| Kortezubi | ulé | 1 |
| Larrabetzu | úle | 1 |
| Laukiz | ulé | 1 |
| Leioa | ulé | 1 |
| Lekeitio | úle | 1 |
| Lemoa | úle | 1 |
| Lemoiz | ulé | 1 |
| Mañaria | úle | 1 |
| Mendata | úle | 1 |
| Mungia | úle | 1 |
| Ondarroa | úle | 1 |
| Orozko | úʎe | 1 |
| Otxandio | úle | 1 |
| Sondika | úle | 1 |
| Zaratamo | úʎe | 1 |
| Zeanuri | úʎe | 1 |
| Zeberio | úʎe | 1 |
| Zollo (Arrankudiaga) | úʎa | 1 |
| Zornotza | úle | 1 |
| Aramaio | úle | 1 |
| Araotz (Oñati) | úle | 1 |
| Arrasate | úle | 1 |
| Eibar | úle | 1 |
| Leintz Gatzaga | úle | 1 |
| Oñati | úle | 1 |
| Aia | iʎé | 2 |
| Amezketa | iʎé | 2 |
| Andoain | iʎé | 2 |
| Arroa (Zestoa) | iʎé | 2 |
| Asteasu | iʎé | 2 |
| Azkoitia | íʎe | 2 |
| Azpeitia | iʎé | 2 |
| Beasain | iʎe | 2 |
| Beizama | iʎé | 2 |
| Bergara | íʎe | 2 |
| Deba | íʎe | 2 |
| Donostia | iʎé | 2 |
| Elduain | iʎɛ | 2 |
| Elgoibar | iʎe | 2 |
| Errezil | iʎé | 2 |
| Ezkio-Itsaso | iʎé | 2 |
| Getaria | iʎé | 2 |
| Hernani | iʎé | 2 |
| Hondarribia | iʎe | 2 |
| Ikaztegieta | iʎe | 2 |
| Lasarte-Oria | iʎé | 2 |
| Legazpi | íʎe | 2 |
| Mendaro | iʎé | 2 |
| Oiartzun | iʎé | 2 |
| Orexa | íʎe | 2 |
| Orio | iʎé | 2 |
| Pasaia | iʎé | 2 |
| Tolosa | iʎé | 2 |
| Urretxu | iʎé | 2 |
| Zegama | iʎé | 2 |
| Alkotz | iʎá | 2 |
| Aniz | iʎé | 2 |
| Arbizu | iʎá | 2 |
| Donamaria | iʎé | 2 |
| Dorrao / Torrano | íʎa | 2 |
| Erratzu | íle | 2 |
| Etxalar | iʎé | 2 |
| Ezkurra | iʎé | 2 |
| Gaintza | iʎé | 2 |
| Goizueta | iʎɛ | 2 |
| Leitza | iʎé | 2 |
| Lekaroz | ílɛ | 2 |
| Sunbilla | iʎé | 2 |
| Urdiain | íle | 2 |
| Zugarramurdi | íle | 2 |
| Ahetze | íle | 2 |
| Arrangoitze | íle | 2 |
| Azkaine | iʎé | 2 |
| Donibane Lohizune | ilé | 2 |
| Hazparne | íle | 2 |
| Hendaia | iʎé | 2 |
| Itsasu | ilé | 2 |
| Mugerre | ile | 2 |
| Sara | ilé | 2 |
| Senpere | íle | 2 |
| Uztaritze | ilé | 2 |
| Aldude | íle | 2 |
| Armendaritze | ilé | 2 |
| Baigorri | ile | 2 |
| Bastida | íle | 2 |
| Beruete | iʎé | 2 |
| Etxaleku | iʎé | 2 |
| Etxarri (Larraun) | iʎí | 2 |
| Igoa | iʎé | 2 |
| Suarbe | íʎe | 2 |
| Azkaine | ileá | 2 |
| Makea | íle | 2 |
| Arnegi | ilé | 2 |
| Bidarrai | íle | 2 |
| Izturitze | ilhe | 2 |
| Suarbe | íʎa | 2 |
| Landibarre | ílea | 2 |
| Ataun | βurúkoiʎé | 3 |
| Landibarre | bírua | 3 |
| Abaurregaina / Abaurrea Alta | βílo | 4 |
| Eugi | βílo | 4 |
| Jaurrieta | bílo | 4 |
| Luzaide / Valcarlos | bílo | 4 |
| Mezkiritz | bílo | 4 |
| Zilbeti | βílo | 4 |
| Bardoze | bílo | 4 |
| Beskoitze | βílo | 4 |
| Makea | βiló | 4 |
| Urketa | bílo | 4 |
| Arboti | bílwak | 4 |
| Arnegi | βiló | 4 |
| Arrueta | bílo | 4 |
| Behorlegi | biló | 4 |
| Bidarrai | βiló | 4 |
| Ezterenzubi | bílo | 4 |
| Gamarte | biló | 4 |
| Garrüze | bílo | 4 |
| Irisarri | bílo | 4 |
| Izturitze | bílho | 4 |
| Jutsi | bilho | 4 |
| Landibarre | biluá | 4 |
| Larzabale | bilho | 4 |
| Uharte Garazi | bílo | 4 |
| Altzai | bilhó | 4 |
| Altzürükü | bílho | 4 |
| Barkoxe | bilho | 4 |
| Domintxaine | bílo | 4 |
| Eskiula | bílho | 4 |
| Larraine | bilho | 4 |
| Montori | bilhó | 4 |
| Pagola | bilhó | 4 |
| Santa Grazi | bílho | 4 |
| Sohüta | bílho | 4 |
| Urdiñarbe | bilhó | 4 |
| Ürrüstoi | bílho | 4 |
| Hazparne | bílo | 4 |
| Itsasu | bílo | 4 |
| Uztaritze | βiló | 4 |
| Aldude | biló | 4 |
| Armendaritze | biló | 4 |
| Bastida | bíle | 4 |
| Domintxaine | bilhó | 4 |
| Eskiula | bilhúk | 4 |
| Landibarre | bílo | 4 |
| Beruete | kalpár | 5 |
| Etxaleku | kalpár | 5 |
| Etxarri (Larraun) | kalpár | 5 |
| Igoa | kalpár | 5 |
| Oderitz | kalpár | 5 |
| Suarbe | kálpar | 5 |
| Alkotz | kalpár a | 5 |
| Gaintza | kalpár | 5 |
| Asteasu | tʃimá | 6 |
| Oiartzun | kíma | 6 |
| Pasaia | símá | 6 |
| Senpere | ileondo | 7 |
Bonus Trak: Dendograma eleganteak aztertuaz
library(factoextra)
dendograma.osoa <- fviz_dend(clus.hair1,
k = 7,
cex = 0.5,
rect = FALSE,
k_colors = "jco")
dendograma.osoa+
geom_hline(yintercept = 0.6, linetype = "dashed") +
labs(title = "Hair in Basque",
subtitle = "ALINE distantzia, Ward.D2, k=?")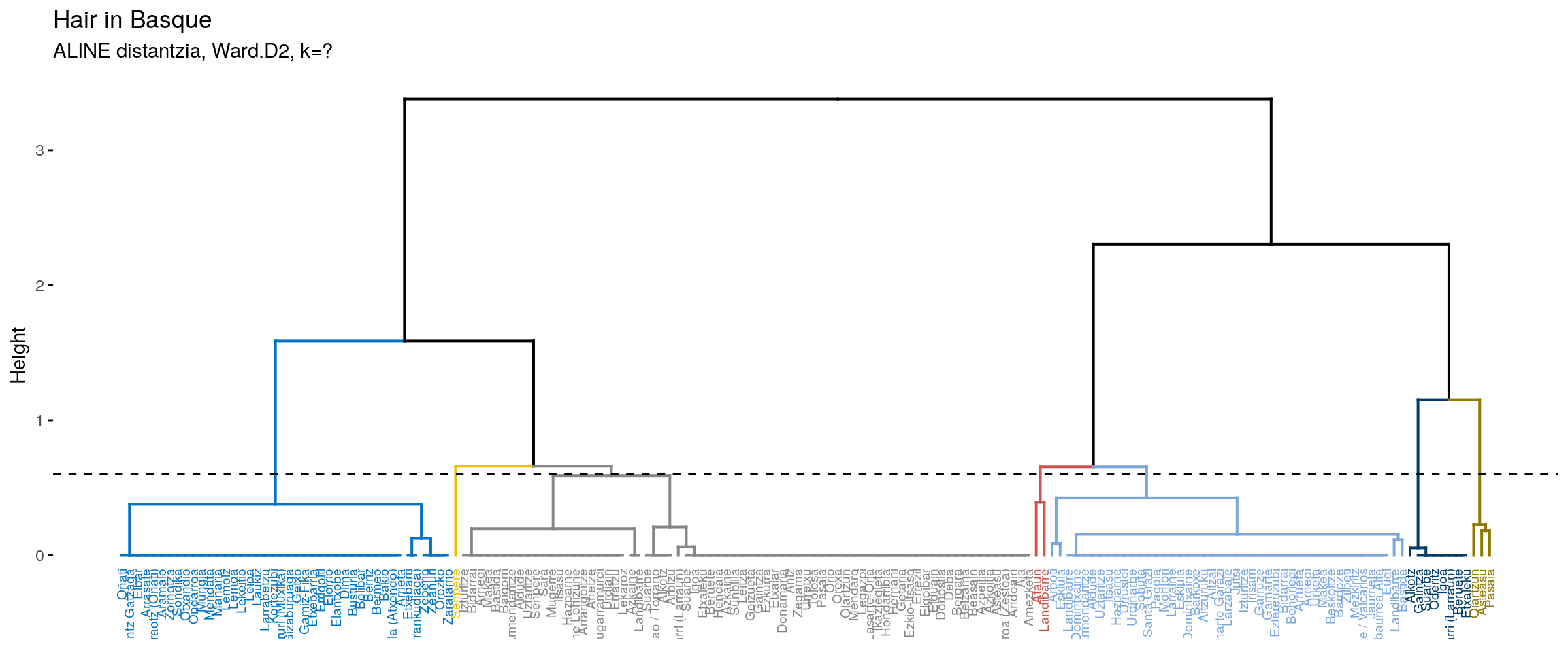
dend_data <- attr(dendograma.osoa, "dendrogram") # Extract dendrogram data
# Cut the dendrogram at height h = 10
dend_cuts <- cut(dend_data, h = 0.6)
# Visualize the truncated version containing
# two branches
fviz_dend(dend_cuts$upper, main = "dendogramaren mozketa: 1.5 distantzian")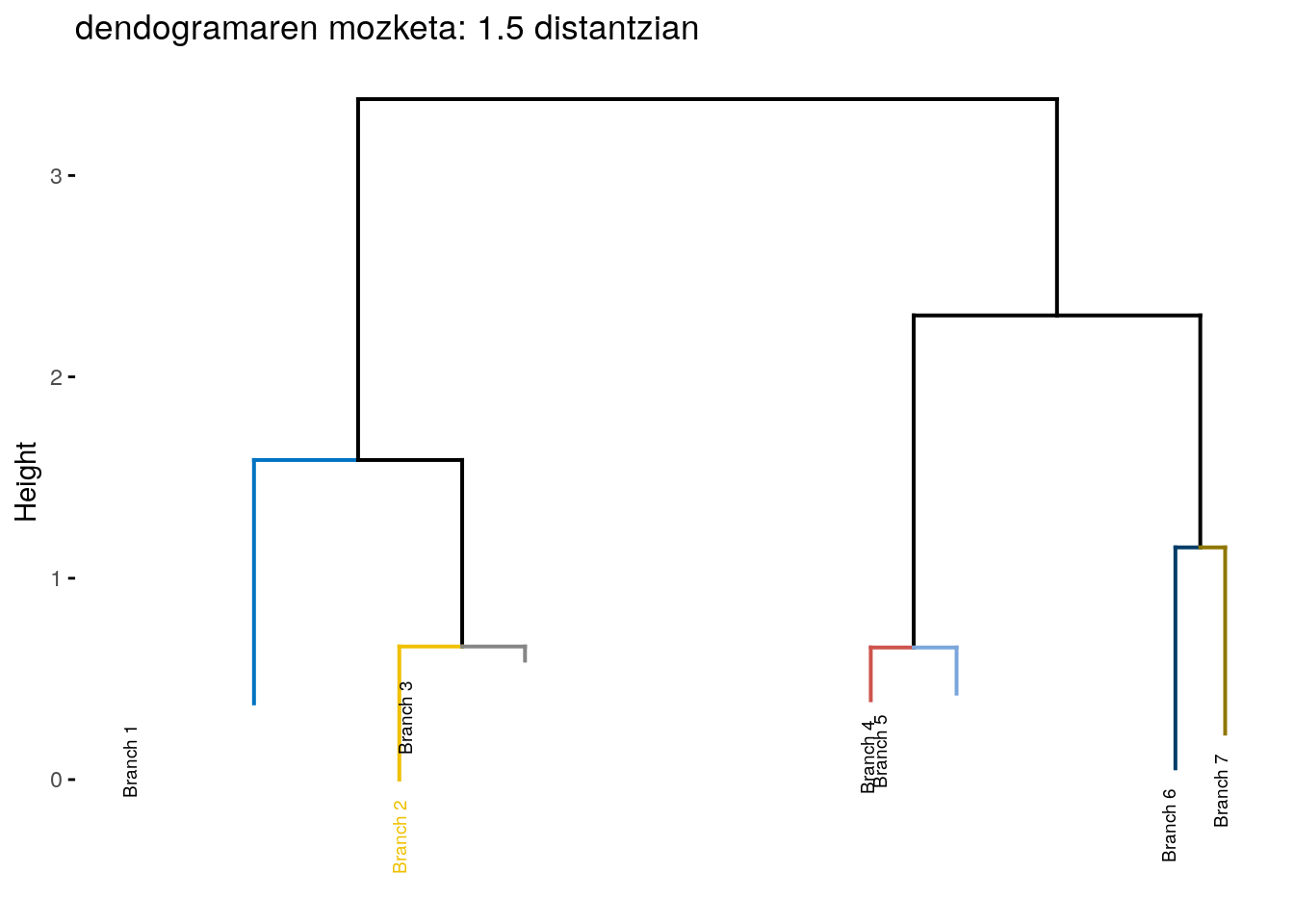
# Plot subtree 1
fviz_dend(dend_cuts$lower[[1]], main = "ULE")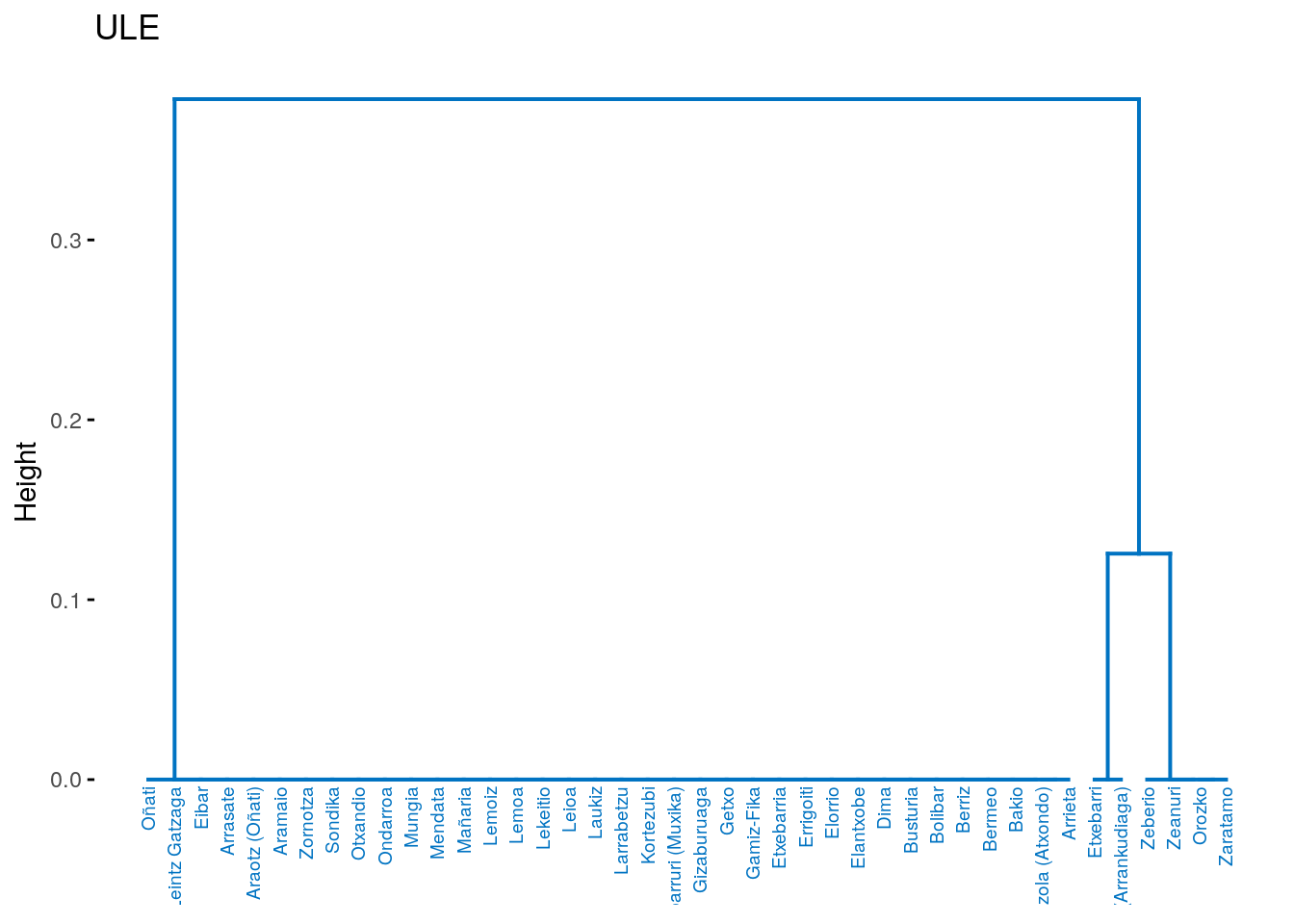
# Plot subtree 2
fviz_dend(dend_cuts$lower[[3]], main = "ILE")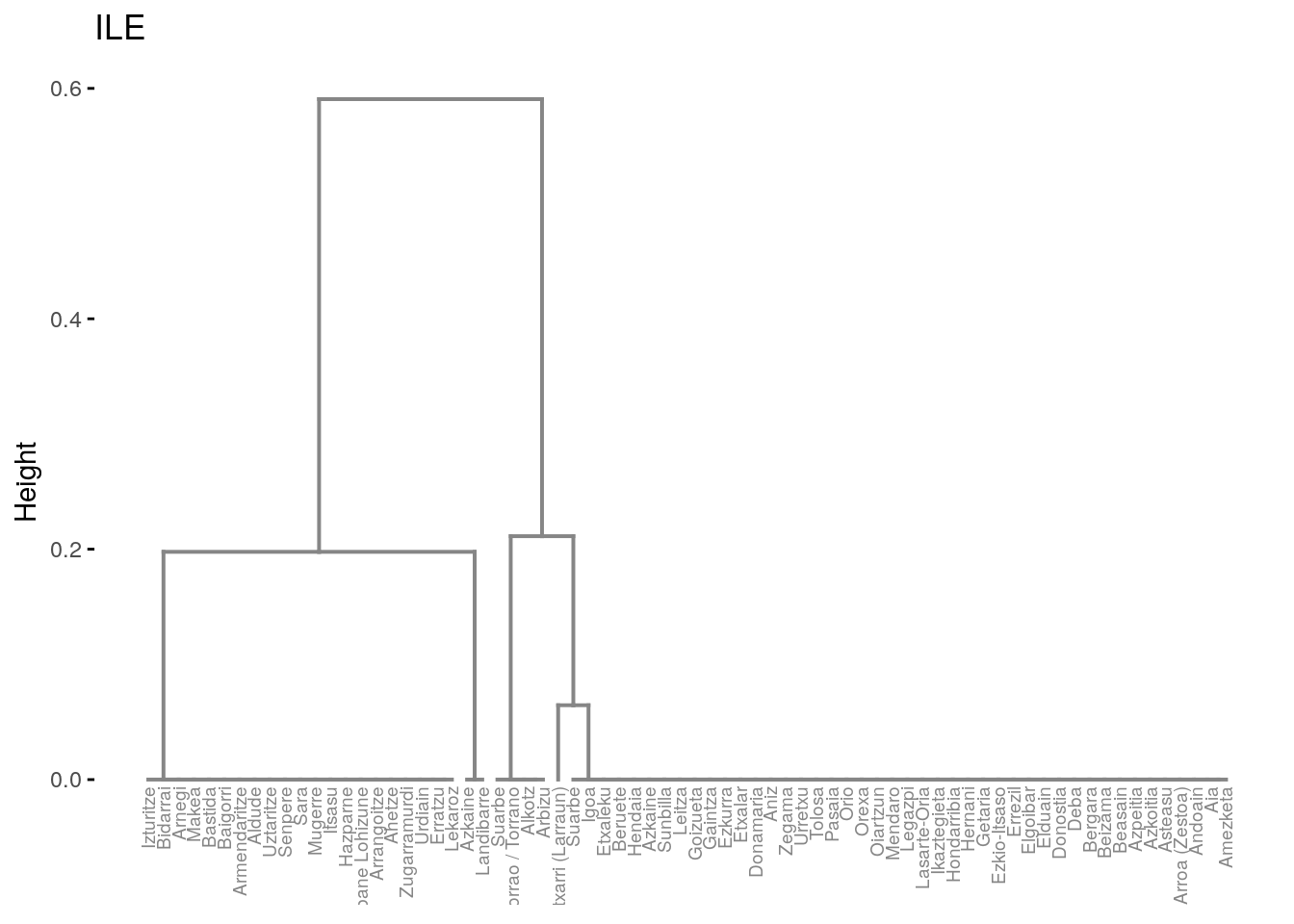
fviz_dend(dend_cuts$lower[[4]], main = "ARAZOA!!")## Warning in min(-diff(our_dend_heights)): no non-missing arguments to min;
## returning Inf
# Plot subtree 2
fviz_dend(dend_cuts$lower[[5]], main = "BILO")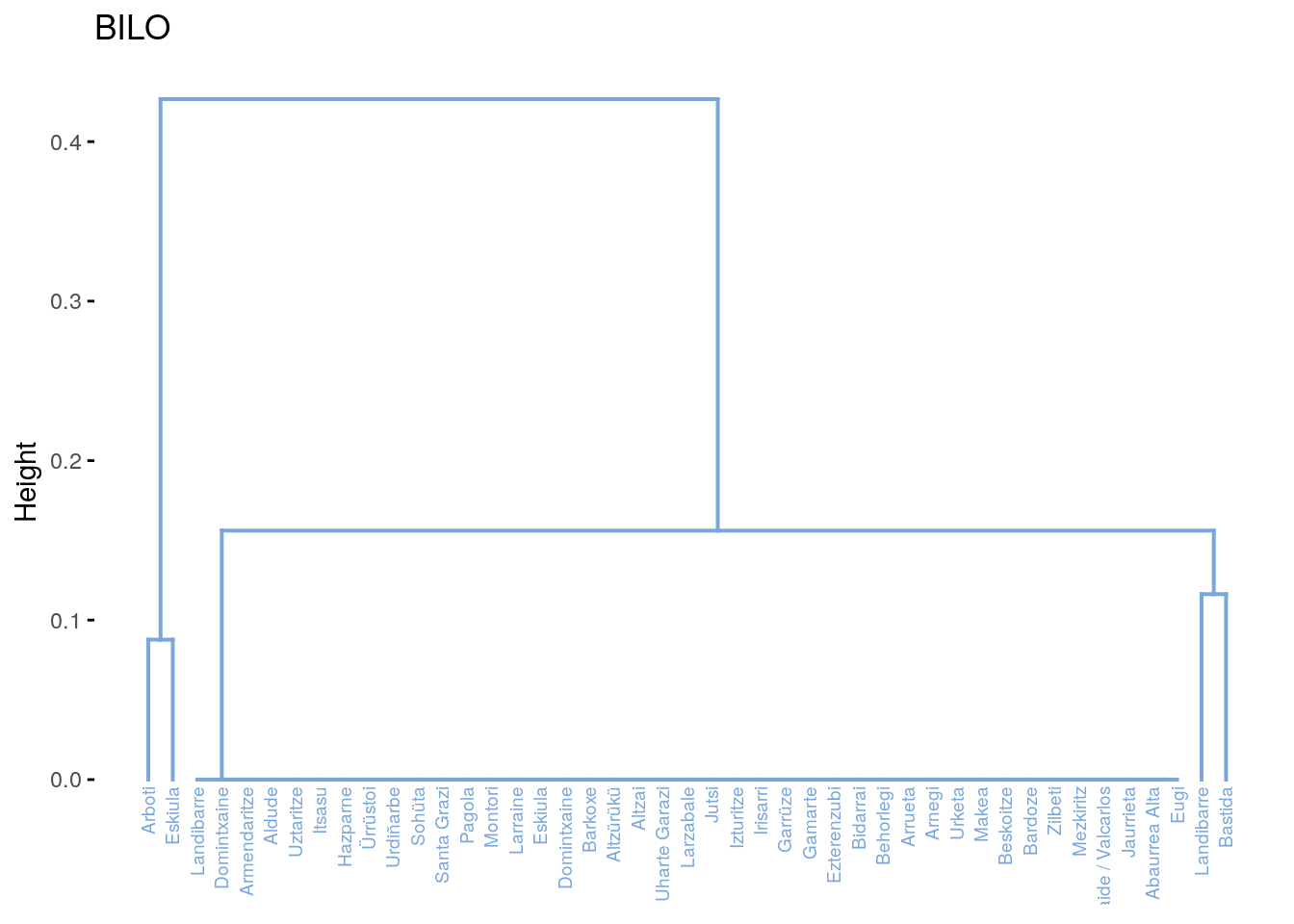
fviz_dend(dend_cuts$lower[[6]], main = "KALPAR")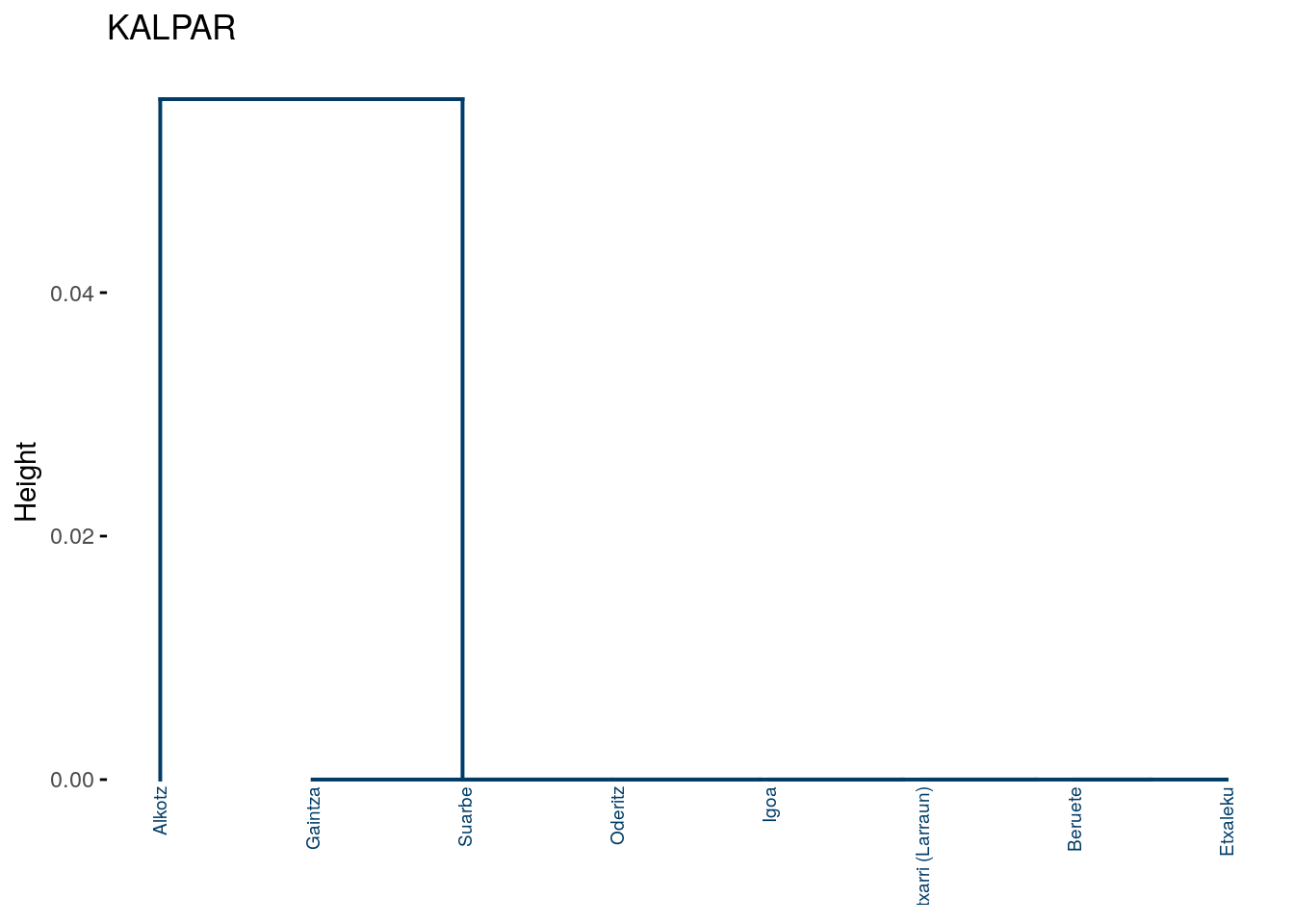
fviz_dend(dend_cuts$lower[[7]], main = "TXIMA")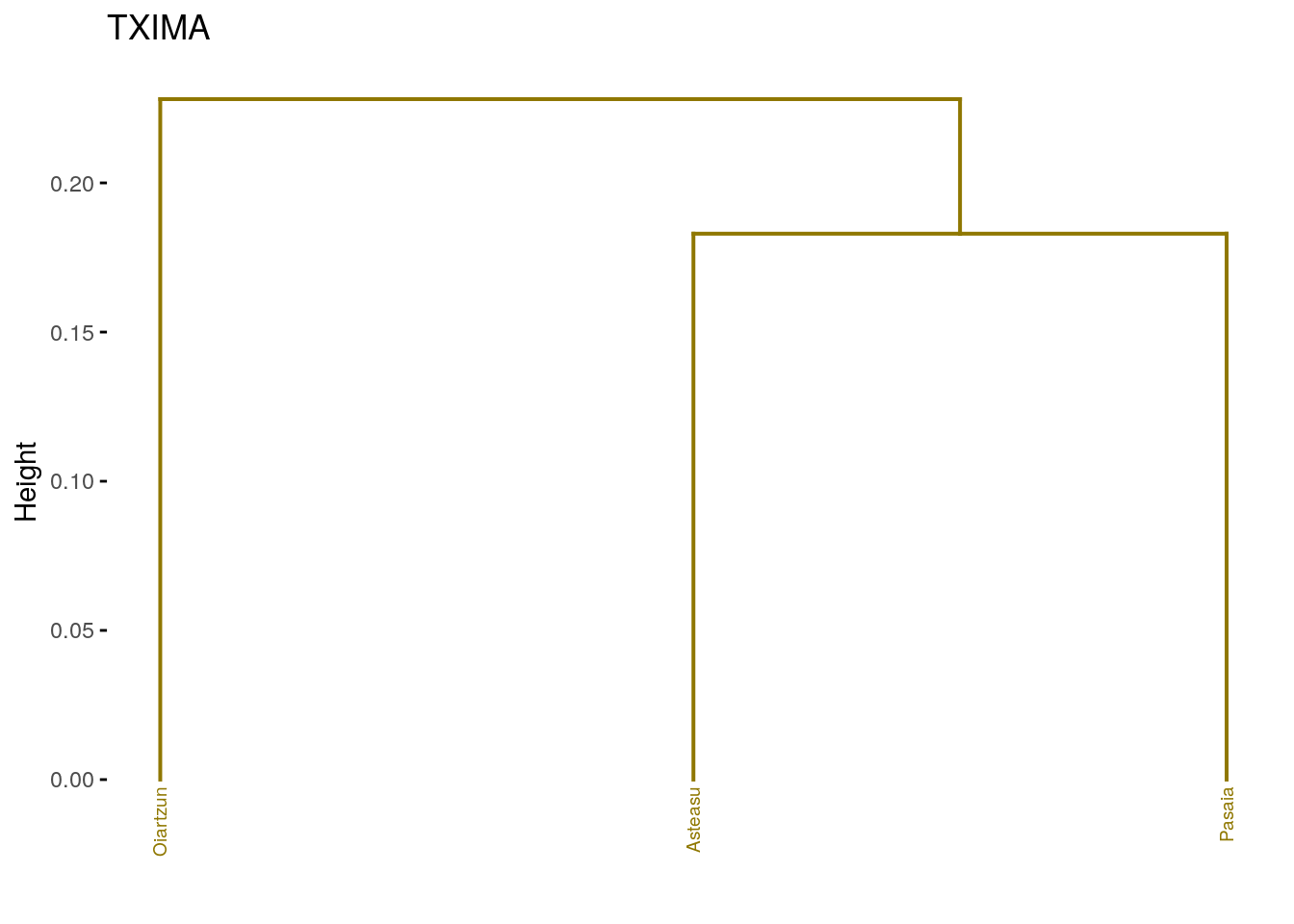
Egitekoak
Multzokatzeko beste eraren batek, agian, eman lezake emaitza hoberik. Emaitzak zorrozteko beste bide bat izan liteke karaktere/karaktere-kateak ordezteko unean.
Erreferentziak
Dialektologia batzordea. 2018. Euskararen Herri Hizkeren Atlasa IX Lexikoa. Vol. 9. Bilbo: Euskaltzaindia. http://www.euskaltzaindia.eus/dok/iker_jagon_tegiak/ehha/9lib/ehha_09.zip.
Downey, Sean S., Brian Hallmark, Murray P. Cox, Peter Norquest, and J. Stephen Lansing. 2008. “Computational Feature-Sensitive Reconstruction of Language Relationships: Developing the ALINE Distance for Comparative Historical Linguistic Reconstruction.” Journal of Quantitative Linguistics 15 (4): 340–69. https://doi.org/10.1080/09296170802326681.
Downey, Sean S., Guowei Sun, and Peter Norquest. 2017. “alineR: An R Package for Optimizing Feature-Weighted Alignments and Linguistic Distances.” The R Journal 9 (1): 138–52. https://journal.r-project.org/archive/2017/RJ-2017-005/index.html.
Kassambara, Mr Alboukadel. 2017. Practical Guide to Cluster Analysis in R: Unsupervised Machine Learning. 1st ed. Multivariate Analysis 1. Erscheinungsort nicht ermittelbar: STHDA.
Aztertu daiteke balioak eurak ere kentzea↩